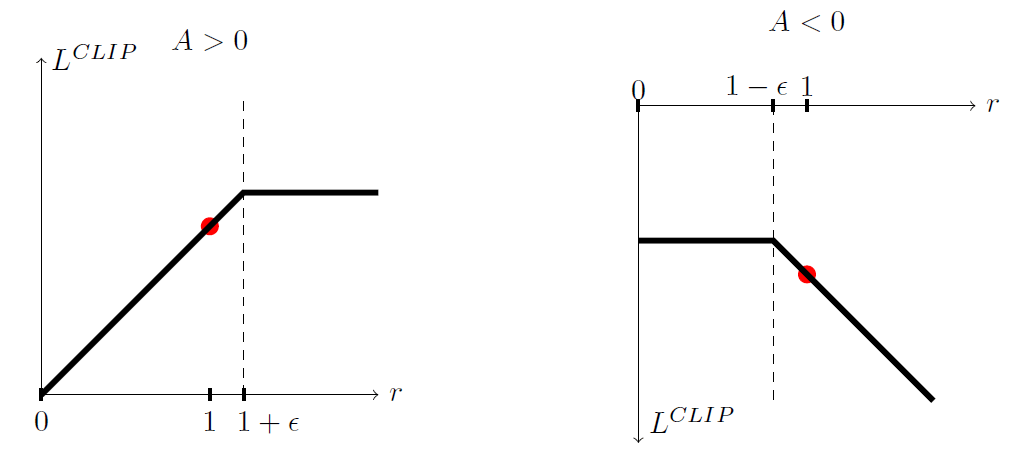找到
5
篇与
论文阅读
相关的结果
-
 深入浅出阅读OpenAI强化学习经典论文《Proximal Policy Optimization Algorithms》 本文深入浅出地解析了OpenAI强化学习经典论文《Proximal Policy Optimization Algorithms》,从工程视角将PPO算法中的“策略”类比为控制器,帮助非专业背景的读者理解其核心思想。文章详细介绍了PPO的提出背景,指出其在解决传统强化学习算法(如DQN、策略梯度方法和TRPO)的稳定性与复杂性难题中的优势。重点分析了PPO的核心创新——“裁剪”目标函数,通过限制策略更新幅度,在保证训练稳定性的同时简化实现。此外,文章还阐述了PPO的三步工作流程(数据收集、优势计算和优化)及其在连续控制任务和雅达利游戏中的卓越实验效果,最终总结了PPO在样本效率、易用性和性能之间的平衡,奠定了其作为强化学习领域主流算法的地位。 小陶本人不是计算机或者数学专业的,其实学习这些经典算法的时候,一个个公式直接看晕乎了。对于有机械工程或者控制工程背景的我们工科生来说,可以将强化学习中的“策略(Policy)”想象成一个控制器,它的目标是学会如何操作一个复杂的系统(比如机器人或游戏角色),以获得最大的累计奖励(比如最快到达终点或获得最高分)。PPO算法就是一种设计这个“控制器”的优秀方法。本文结合论文的原文并且适当使用AI进行整理。如果明显的错误,欢迎指出交流。 论文原文:Proximal Policy Optimization Algorithms - arXiv:1707.06347 PPO的提出背景:为什么我们需要PPO? 在PPO被提出之前,主流的强化学习算法主要有三类,但它们都各有短处: (1)深度Q学习 (DQN): 这类算法在处理像雅达利(Atari)游戏这样拥有离散动作(比如上、下、左、右)的环境中表现优异 。但它很难被应用到动作是连续的场景中(比如控制机器人关节的角度) ,并且在一些简单问题上有时也表现不佳 。 (2)“香草”策略梯度 (Vanilla Policy Gradient, PG): 这类算法可以直接优化策略,能处理连续动作问题。但它有一个很大的缺点:训练过程非常不稳定,对参数敏感。想象一下你在调试一个控制器参数,稍微调大一点,系统就可能直接崩溃。PG算法就有类似的问题,它在更新策略时步子迈得太大,很容易导致策略“学废了”,性能急剧下降 。 (3)信任区域策略优化 (Trust Region Policy Optimization, TRPO): TRPO是为了解决PG算法不稳定的问题而设计的。它的核心思想是:在更新策略时,给新策略加一个“信任区域”的约束,确保新策略不会和旧策略偏离太远,从而保证了学习过程的稳定。TRPO效果很好,但它的算法实现异常复杂 ,需要用到二阶优化,并且与一些常见的网络结构(如参数共享、Dropout)不兼容 。 PPO的目标就是: 创造一种新算法,既能拥有TRPO的稳定性和可靠性能,又能像PG算法一样简单,只用一阶优化(也就是我们常用的梯度下降/上升),更容易实现和应用 。 PPO的核心思想:神奇的“裁剪”目标函数 PPO的精髓在于它设计了一个巧妙的“代理”目标函数(Surrogate Objective Function)。在更新策略时,我们优化的不是真实的回报,而是这个代理目标,通过优化它来间接提升策略。 要理解这个目标函数,我们先来看一个关键的比率:概率比率 (Probability Ratio)。 $$ r _ { t } ( \theta ) = \frac { \pi _ { \theta } ( a _ { t } | s _ { t } ) } { \pi _ { \theta _ { o l d } } ( a _ { t } | s _ { t } ) } $$ 分子是新策略在状态St下采取动作at的概率; 分母是旧策略在同样状态下采取同样动作的概率; 这个比值 $r _ { t }$ 度量了新旧策略的差异。如果 $r_t>1$,说明新策略更倾向于采取这个动作;如果$ r_t<1$,则说明新策略更不倾向于采取这个动作 。 传统的策略梯度算法的目标函数可以简化为 : $$ L ^ { C P I } ( \theta ) = r _ { t } ( \theta ) \hat { A } _ { t } $$其中 $ \hat { A } _ { t } $ 是优势函数 (Advantage Function),它衡量了在状态$ s _ { t } $采取动作$ a _ { t } $究竟有多好。如果 $ \hat { A } _ { t } $ \>0,说明这个动作比平均水平要好;反之则不好。 所以,优化的目标就是:如果一个动作是“好”的,就增大它的概率,如果一个动作是“坏”的,就减小它的概率。 那么,问题来了,如果毫无限制地增大$r _ { t }$,就可能导致策略更新步子太大,这就是PG算法不稳定的根源 。PPO的解决方案是裁剪 (Clipping)。 PPO的目标函数如下: $$ L ^ { C L I P } ( \theta ) = \hat { \mathbb { E } } _ { t } \left[ \operatorname* { m i n } \left( r _ { t } ( \theta ) \hat { A } _ { t } , \operatorname { c l i p } ( r _ { t } ( \theta ) , 1 - \epsilon , 1 + \epsilon ) \hat { A } _ { t } \right) \right] $$这里的$\epsilon$是一个超参数,通常取0.2左右 。这个公式看起来复杂,但思想很直观,我们可以把它看作一个“带有限位器的激励系统”(如下图所示): 带有限位器的激励系统图片 当动作是“好”的 $( \hat { A } _ { t } > 0 )$: 目标函数变为$ \operatorname* { m i n } ( r _ { t } \hat { A } _ { t } , ( 1 + \epsilon ) \hat { A } _ { t } ) $ 我们希望增大$r _ { t }$来获得更大的回报,但函数外部的 min 操作给这个回报设置了一个上限。一旦$r _ { t }$超过 1+ϵ,回报就不会再增加了。 这就好比: 你做得好,就给你奖励,但奖励有个上限,防止你因为一次超常发挥就变得过于激进,从而保证了稳定性。 当动作是“坏”的$( \hat { A } _ { t } < 0 )$: 目标函数变为${ m i n } ( r _ { t } \hat { A } _ { t } , ( 1 - \epsilon ) \hat { A } _ { t } )$ 我们希望减小$r _ { t }$,但如果优化的过程中,算法错误地增大了$r _ { t }$(比如超过了 1+ϵ),$r _ { t } \hat { A } _ { t }$这一项会变成一个很大的负数,给予一个严厉的惩罚。 clip 的作用是,当$r _ { t }$减小到1−ϵ 以下时,目标函数的值不再变化 。这同样限制了单步更新的幅度。 这就好比: 你做得不好,就要接受惩罚。这个机制确保了你不会因为想逃避惩罚而做出过于保守或奇怪的动作,同时也对错误方向的更新给予重罚。 通过上述的约束,这个“裁剪”的目标函数通过限制策略更新的幅度,巧妙地将TRPO的“信任区域”思想用一种更简单的方式实现了,使得算法既稳定又易于实现 。 PPO如何Work:三步走的循环 PPO作为一个“演员-评论家(Actor-Critic)”风格的算法,其工作流程非常清晰 : 第一步:数据收集 首先,我们有N个并行的“演员”(Actor),它们使用当前的策略$\pi _ { \theta _ { o l d } }$与环境互动,各自收集T个时间步的数据(状态、动作、奖励等) 。 第二步:优势计算 利用收集到的数据,计算每个时间步的优势函数估计值$( \hat { A } _ { t } $。这通常通过一种叫做“广义优势估计 (GAE)”的技术来完成 。 第三步:优化 将收集到的 NT 条数据作为一个批次(batch),用这个批次的数据来优化上面提到的 目标函数 $L ^ { C L I P } $。 关键点:PPO会用同一批数据,通过随机梯度上升(如Adam优化器)进行多轮(K epochs)的优化 。这极大地提高了数据的利用率,也是它相比于PG算法数据效率更高的原因。因为有“裁剪”机制的保护,多轮更新也不会导致策略崩溃 。 这三步完成后,更新策略参数,然后无限循环下去,策略就会变得越来越好。 PPO实验效果 它真的好用吗?答案是肯定的。论文通过大量的实验证明了PPO的有效性。 在连续控制任务上(如模拟机器人行走):论文首先验证了“裁剪”目标函数的有效性。不带任何限制的版本性能很差,甚至比随机策略还糟糕,而带有裁剪的版本(ϵ=0.2)在所有变体中得分最高 。在与其他主流算法(如TRPO, A2C)的对比中,PPO在绝大多数任务上都取得了最好的性能,学习速度更快,最终表现也更优越 (具体可见论文Figure 3的曲线图)。 PPO的有效性图片 在雅达利游戏上(离散控制任务),PPO同样表现出色。论文在49个游戏上对比了PPO, A2C和ACER。如果衡量“学习速度”(整个训练过程的平均分),PPO在30个游戏中胜出,遥遥领先 。如果衡量“最终性能”(训练最后100个回合的平均分),PPO的表现也极具竞争力,虽然胜出游戏数量少于ACER,但考虑到PPO的实现简单得多,这个结果已经非常惊人了 。 雅达利游戏上(离散控制任务)图片 论文总结 PPO通过引入一个创新的裁剪代理目标函数,成功地实现了与复杂算法TRPO相媲美的稳定性和性能,同时保持了代码实现的简洁性 。它解决了传统策略梯度方法更新步长难以确定、容易崩溃的问题,也避免了信任区域方法的复杂计算。总的来说,PPO在样本效率、实现简单性和性能表现之间找到了一个绝佳的平衡点 ,这也是它至今仍然是强化学习研究和应用领域最常用和最受欢迎的算法之一的原因。
深入浅出阅读OpenAI强化学习经典论文《Proximal Policy Optimization Algorithms》 本文深入浅出地解析了OpenAI强化学习经典论文《Proximal Policy Optimization Algorithms》,从工程视角将PPO算法中的“策略”类比为控制器,帮助非专业背景的读者理解其核心思想。文章详细介绍了PPO的提出背景,指出其在解决传统强化学习算法(如DQN、策略梯度方法和TRPO)的稳定性与复杂性难题中的优势。重点分析了PPO的核心创新——“裁剪”目标函数,通过限制策略更新幅度,在保证训练稳定性的同时简化实现。此外,文章还阐述了PPO的三步工作流程(数据收集、优势计算和优化)及其在连续控制任务和雅达利游戏中的卓越实验效果,最终总结了PPO在样本效率、易用性和性能之间的平衡,奠定了其作为强化学习领域主流算法的地位。 小陶本人不是计算机或者数学专业的,其实学习这些经典算法的时候,一个个公式直接看晕乎了。对于有机械工程或者控制工程背景的我们工科生来说,可以将强化学习中的“策略(Policy)”想象成一个控制器,它的目标是学会如何操作一个复杂的系统(比如机器人或游戏角色),以获得最大的累计奖励(比如最快到达终点或获得最高分)。PPO算法就是一种设计这个“控制器”的优秀方法。本文结合论文的原文并且适当使用AI进行整理。如果明显的错误,欢迎指出交流。 论文原文:Proximal Policy Optimization Algorithms - arXiv:1707.06347 PPO的提出背景:为什么我们需要PPO? 在PPO被提出之前,主流的强化学习算法主要有三类,但它们都各有短处: (1)深度Q学习 (DQN): 这类算法在处理像雅达利(Atari)游戏这样拥有离散动作(比如上、下、左、右)的环境中表现优异 。但它很难被应用到动作是连续的场景中(比如控制机器人关节的角度) ,并且在一些简单问题上有时也表现不佳 。 (2)“香草”策略梯度 (Vanilla Policy Gradient, PG): 这类算法可以直接优化策略,能处理连续动作问题。但它有一个很大的缺点:训练过程非常不稳定,对参数敏感。想象一下你在调试一个控制器参数,稍微调大一点,系统就可能直接崩溃。PG算法就有类似的问题,它在更新策略时步子迈得太大,很容易导致策略“学废了”,性能急剧下降 。 (3)信任区域策略优化 (Trust Region Policy Optimization, TRPO): TRPO是为了解决PG算法不稳定的问题而设计的。它的核心思想是:在更新策略时,给新策略加一个“信任区域”的约束,确保新策略不会和旧策略偏离太远,从而保证了学习过程的稳定。TRPO效果很好,但它的算法实现异常复杂 ,需要用到二阶优化,并且与一些常见的网络结构(如参数共享、Dropout)不兼容 。 PPO的目标就是: 创造一种新算法,既能拥有TRPO的稳定性和可靠性能,又能像PG算法一样简单,只用一阶优化(也就是我们常用的梯度下降/上升),更容易实现和应用 。 PPO的核心思想:神奇的“裁剪”目标函数 PPO的精髓在于它设计了一个巧妙的“代理”目标函数(Surrogate Objective Function)。在更新策略时,我们优化的不是真实的回报,而是这个代理目标,通过优化它来间接提升策略。 要理解这个目标函数,我们先来看一个关键的比率:概率比率 (Probability Ratio)。 $$ r _ { t } ( \theta ) = \frac { \pi _ { \theta } ( a _ { t } | s _ { t } ) } { \pi _ { \theta _ { o l d } } ( a _ { t } | s _ { t } ) } $$ 分子是新策略在状态St下采取动作at的概率; 分母是旧策略在同样状态下采取同样动作的概率; 这个比值 $r _ { t }$ 度量了新旧策略的差异。如果 $r_t>1$,说明新策略更倾向于采取这个动作;如果$ r_t<1$,则说明新策略更不倾向于采取这个动作 。 传统的策略梯度算法的目标函数可以简化为 : $$ L ^ { C P I } ( \theta ) = r _ { t } ( \theta ) \hat { A } _ { t } $$其中 $ \hat { A } _ { t } $ 是优势函数 (Advantage Function),它衡量了在状态$ s _ { t } $采取动作$ a _ { t } $究竟有多好。如果 $ \hat { A } _ { t } $ \>0,说明这个动作比平均水平要好;反之则不好。 所以,优化的目标就是:如果一个动作是“好”的,就增大它的概率,如果一个动作是“坏”的,就减小它的概率。 那么,问题来了,如果毫无限制地增大$r _ { t }$,就可能导致策略更新步子太大,这就是PG算法不稳定的根源 。PPO的解决方案是裁剪 (Clipping)。 PPO的目标函数如下: $$ L ^ { C L I P } ( \theta ) = \hat { \mathbb { E } } _ { t } \left[ \operatorname* { m i n } \left( r _ { t } ( \theta ) \hat { A } _ { t } , \operatorname { c l i p } ( r _ { t } ( \theta ) , 1 - \epsilon , 1 + \epsilon ) \hat { A } _ { t } \right) \right] $$这里的$\epsilon$是一个超参数,通常取0.2左右 。这个公式看起来复杂,但思想很直观,我们可以把它看作一个“带有限位器的激励系统”(如下图所示): 带有限位器的激励系统图片 当动作是“好”的 $( \hat { A } _ { t } > 0 )$: 目标函数变为$ \operatorname* { m i n } ( r _ { t } \hat { A } _ { t } , ( 1 + \epsilon ) \hat { A } _ { t } ) $ 我们希望增大$r _ { t }$来获得更大的回报,但函数外部的 min 操作给这个回报设置了一个上限。一旦$r _ { t }$超过 1+ϵ,回报就不会再增加了。 这就好比: 你做得好,就给你奖励,但奖励有个上限,防止你因为一次超常发挥就变得过于激进,从而保证了稳定性。 当动作是“坏”的$( \hat { A } _ { t } < 0 )$: 目标函数变为${ m i n } ( r _ { t } \hat { A } _ { t } , ( 1 - \epsilon ) \hat { A } _ { t } )$ 我们希望减小$r _ { t }$,但如果优化的过程中,算法错误地增大了$r _ { t }$(比如超过了 1+ϵ),$r _ { t } \hat { A } _ { t }$这一项会变成一个很大的负数,给予一个严厉的惩罚。 clip 的作用是,当$r _ { t }$减小到1−ϵ 以下时,目标函数的值不再变化 。这同样限制了单步更新的幅度。 这就好比: 你做得不好,就要接受惩罚。这个机制确保了你不会因为想逃避惩罚而做出过于保守或奇怪的动作,同时也对错误方向的更新给予重罚。 通过上述的约束,这个“裁剪”的目标函数通过限制策略更新的幅度,巧妙地将TRPO的“信任区域”思想用一种更简单的方式实现了,使得算法既稳定又易于实现 。 PPO如何Work:三步走的循环 PPO作为一个“演员-评论家(Actor-Critic)”风格的算法,其工作流程非常清晰 : 第一步:数据收集 首先,我们有N个并行的“演员”(Actor),它们使用当前的策略$\pi _ { \theta _ { o l d } }$与环境互动,各自收集T个时间步的数据(状态、动作、奖励等) 。 第二步:优势计算 利用收集到的数据,计算每个时间步的优势函数估计值$( \hat { A } _ { t } $。这通常通过一种叫做“广义优势估计 (GAE)”的技术来完成 。 第三步:优化 将收集到的 NT 条数据作为一个批次(batch),用这个批次的数据来优化上面提到的 目标函数 $L ^ { C L I P } $。 关键点:PPO会用同一批数据,通过随机梯度上升(如Adam优化器)进行多轮(K epochs)的优化 。这极大地提高了数据的利用率,也是它相比于PG算法数据效率更高的原因。因为有“裁剪”机制的保护,多轮更新也不会导致策略崩溃 。 这三步完成后,更新策略参数,然后无限循环下去,策略就会变得越来越好。 PPO实验效果 它真的好用吗?答案是肯定的。论文通过大量的实验证明了PPO的有效性。 在连续控制任务上(如模拟机器人行走):论文首先验证了“裁剪”目标函数的有效性。不带任何限制的版本性能很差,甚至比随机策略还糟糕,而带有裁剪的版本(ϵ=0.2)在所有变体中得分最高 。在与其他主流算法(如TRPO, A2C)的对比中,PPO在绝大多数任务上都取得了最好的性能,学习速度更快,最终表现也更优越 (具体可见论文Figure 3的曲线图)。 PPO的有效性图片 在雅达利游戏上(离散控制任务),PPO同样表现出色。论文在49个游戏上对比了PPO, A2C和ACER。如果衡量“学习速度”(整个训练过程的平均分),PPO在30个游戏中胜出,遥遥领先 。如果衡量“最终性能”(训练最后100个回合的平均分),PPO的表现也极具竞争力,虽然胜出游戏数量少于ACER,但考虑到PPO的实现简单得多,这个结果已经非常惊人了 。 雅达利游戏上(离散控制任务)图片 论文总结 PPO通过引入一个创新的裁剪代理目标函数,成功地实现了与复杂算法TRPO相媲美的稳定性和性能,同时保持了代码实现的简洁性 。它解决了传统策略梯度方法更新步长难以确定、容易崩溃的问题,也避免了信任区域方法的复杂计算。总的来说,PPO在样本效率、实现简单性和性能表现之间找到了一个绝佳的平衡点 ,这也是它至今仍然是强化学习研究和应用领域最常用和最受欢迎的算法之一的原因。
-
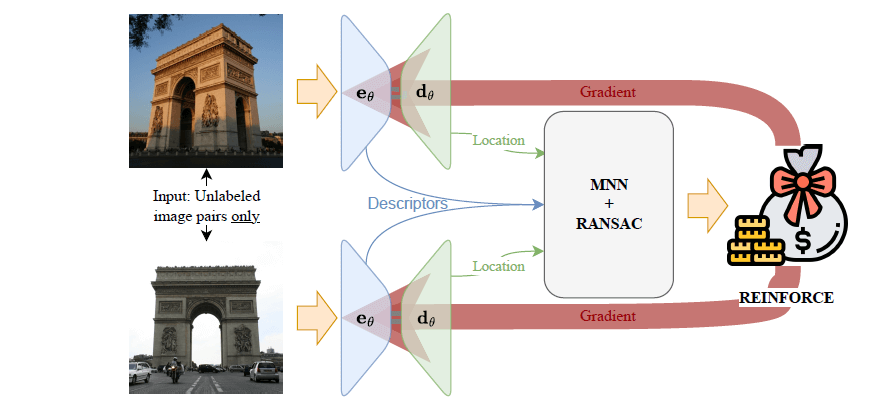
ICCV 2025 论文分享《RIPE: Reinforcement Learning on Unlabeled Image Pairs for Robust Keypoint Extraction》 本文介绍了一种创新的弱监督关键点提取框架 RIPE,它利用强化学习技术,仅需图像对的二元场景匹配标签(是否为同一场景)即可完成训练,无需依赖精确的位姿、深度信息或复杂的人工数据增强。RIPE 将关键点选择建模为强化学习问题,通过概率性采样关键点、多尺度描述符生成以及基于几何验证的奖励机制,有效提升了模型在剧烈光照、天气变化等真实场景下的鲁棒性。实验表明,RIPE 在 MegaDepth、HPatches、Aachen Day-Night 和 Boreas 等多个基准测试中取得了与现有全监督方法相当甚至更优的性能,显著推动了弱监督关键点提取技术的发展。 开源地址: RIPE - Github 论文阅读:RIPE: Reinforcement Learning on Unlabeled Image Pairs for Robust Keypoint Extraction 一、 解决的问题 传统的关键点检测方法(如 SIFT 、ORB )依赖手工设计的特征,在面对剧烈的光照变化、天气变化或长时间跨度的图像匹配任务时,性能会显著下降 。为了克服这些限制,研究人员转向了基于深度学习的方法。 然而,当前主流(SOTA)的深度学习方法大多存在以下依赖问题: 依赖强大的监督信息: 许多方法如 DeDoDe、DISK 和 ALIKED 依赖于具有精确位姿和深度信息的数据集(如 MegaDepth )。这些数据集的构建过程复杂,通常需要通过运动恢复结构(SfM)技术生成,而SfM本身又依赖于SIFT等传统关键点 。这限制了训练数据的规模和多样性。 依赖人工数据增强: 另一类方法如 SuperPoint 和 SiLK 通过对图像进行人工变换(如单应性变换)来生成训练数据 。这种方式难以完全模拟真实世界中复杂的光照、天气和季节变化,导致模型在真实场景中的泛化能力不足 。 RIPE 旨在解决的核心问题是: 如何在弱监督条件下,仅利用“是否为同一场景”的二元标签,训练出一个在各种真实世界条件下都表现鲁棒的关键点检测与描述模型,从而摆脱对精确位姿、深度信息或复杂人工数据增强的依赖 。 二、 使用的方法 整体图片 关键点提取图片 为了解决关键点选择过程不可微的问题,并适应弱监督的训练方式,RIPE 创新地将关键点提取任务构建为一个强化学习(RL)问题 。其核心思想是,将网络看作一个“智能体”,它“学习”在一幅图像(状态)中选择最佳的关键点位置(动作),并通过匹配结果(奖励)来优化其选择策略。该方法主要包含以下几个关键部分: (1)基于强化学习的概率性关键点选择: 模型(一个Encoder-Decoder网络)为输入图像生成一个热力图(heatmap)。 热力图被划分为网格单元(grid cells),在每个单元格内,模型会基于logit值概率性地采样一个关键点位置 。 同时,模型会学习一个“接受概率”,用于判断该单元格是否适合提取关键点,从而可以主动放弃天空、过曝等区域 。 这个过程在代码 ripe/models/ripe.py 中的 KeypointSampler 类中实现。 (2)基于多尺度特征的描述符生成 为了让描述符更具辨别力,RIPE不只使用编码器最后一层的特征,而是采用超列(Hyper-column)技术 。 从编码器的多个中间层提取特征,并将这些不同尺度的特征在关键点位置进行插值和拼接,形成一个包含丰富上下文信息的描述符。 这部分在代码 ripe/models/upsampler/hypercolumn_features.py 中实现。 (3)基于几何约束的奖励机制 这是整个强化学习框架的核心。奖励(Reward)直接来源于图像对的匹配结果。 对于一对图像,模型提取的关键点和描述符会先进行相互最近邻匹配(Mutual Nearest Neighbor, MNN) 。 然后,通过 RANSAC 算法结合基本矩阵(Fundamental Matrix)估计来滤除不符合对极几何约束的匹配点 。 最终的奖励信号就是通过几何验证的内点(inliers)数量 。 对于正样本对(同一场景),奖励为正,鼓励网络找到更多可匹配且符合几何一致性的关键点 。对于负样本对(不同场景),奖励为负(惩罚),抑制网络在不同场景间找到错误的匹配 。 这个奖励计算过程虽然不可微,但在强化学习中仅用作一个标量信号,通过 REINFORCE 算法 更新网络权重。 (4)辅助性的描述符损失函数 为了进一步增强描述符的判别能力,RIPE还引入了一个辅助的对比损失函数(Descriptor Loss)。 对于正样本对,它会拉近匹配内点描述符之间的距离,同时推远它们与其他描述符的距离 。 对于负样本对,它会推远所有错误匹配的描述符之间的距离 。 该损失函数的实现在 ripe/losses/contrastive_loss.py 中。 三、具体实现的流程 mgd5yoqf.png图片 (1)网络结构 编码器(Encoder): 使用在 ImageNet 上预训练的 VGG-19 网络 。代码位于ripe/models/backbones/vgg.py。 解码器(Decoder): 借鉴了 DeDoDe 的设计,使用了深度可分离卷积的精炼模块(ConvRefiner)来从编码器特征生成热力图 。代码位于ripe/models/backbones/vgg_utils.py。 整体模型: 将上述模块组合在 ripe/models/ripe.py 的 RIPE 类中。 (2)数据处理与训练流程 (ripe/train.py) 1)数据加载: 训练数据是成对的图像,每对带有一个二元标签(1表示同一场景,-1表示不同场景)。代码中通过DatasetCombinator (ripe/data/datasets/dataset_combinator.py) 可以灵活地组合来自不同数据集(如 MegaDepth、Tokyo 24/7)的数据。 2)前向传播:一对图像 (I, I') 分别输入到 RIPE 网络中,得到各自的热力图、粗描述符等输出 。通过KeypointSampler 概率性地采样关键点位置 kpts1, kpts2 及其对数概率 logprobs1, logprobs2 。使用 HyperColumnFeatures 在采样出的关键点位置提取多尺度描述符 desc1, desc2 。 3)匹配与奖励计算:使用 Kornia 库的DescriptorMatcher 进行MNN匹配,得到初始匹配对 。使用 PoseLib 库进行鲁棒的基本矩阵估计(RANSAC),筛选出内点(inliers)。这部分由 ripe/matcher/concurrent_matcher.py 调度。根据内点数量和样本对的标签(正/负),计算出奖励矩阵 dense_rewards。该逻辑在 ripe/utils/utils.py 的 get_rewards 函数中。 4)损失计算与反向传播: 策略损失(Policy Loss): 将奖励 dense_rewards 与关键点的联合对数概率 dense_logprobs 相乘,这是 REINFORCE 算法的核心。目标是最大化奖励期望 。 描述符损失(Descriptor Loss): 计算辅助的对比损失 loss_desc_stack。 正则化项: 包含一个小的惩罚项 loss_kp_stack,防止网络生成概率过低的关键点 。 最终损失: L = L_policy + L_kp + ψ * L_desc ,其中 ψ 是平衡权重的超参数 。 通过 Fabric(PyTorch Lightning 的一个库)进行反向传播和梯度更新。 四、 最终的效果 RIPE 在多个基准测试中取得了具有竞争力的结果,证明了其弱监督学习框架的有效性。 标准基准测试: MegaDepth-1500(相对位姿估计): 在这个广泛使用的基准上,RIPE 的性能(以AUC@角度误差度量)与当前顶尖的稀疏特征方法 ALIKED 非常接近,并且优于同样基于VGG的DeDoDe 。值得注意的是,RIPE 是唯一一个在不使用位姿/深度或人工单应性变换监督的情况下达到该性能水平的方法 。 HPatches(单应性估计): 在此数据集上,RIPE 的表现同样与 SOTA 方法 SiLK 和 DeDoDe 相当 。 真实世界挑战场景: Aachen Day-Night(昼夜户外定位): 这是 RIPE 方法优势最突出的地方。当仅使用 MegaDepth 数据集训练时,RIPE 的夜间定位性能已明显优于 DeDoDe 。当在训练数据中混入 20% 的 Tokyo 24/7 数据集(一个包含昼夜变化的图像对,但没有位姿信息)后,RIPE 的夜间定位精度获得了大幅提升 。这充分证明了 RIPE 能够有效利用多样化的弱监督数据来增强模型的鲁棒性 。 Boreas(恶劣天气户外定位): 在包含雨、雪、黑夜等恶劣天气条件的 Boreas 数据集上,RIPE 同样展现了其竞争力。通过在训练中加入 ACDC 数据集(一个包含恶劣天气图像的数据集),RIPE 的性能也得到了提升 。 总结来说,RIPE 最大的亮点在于它简化了数据依赖,仅需简单的二元标签就能进行有效训练。这使得模型可以利用更多样、更贴近真实世界的训练数据,从而在光照和天气变化剧烈的挑战性场景中展现出更强的泛化能力和鲁棒性 。尽管其监督信号远弱于其他方法,但最终性能却能与SOTA方法相媲美,标志着关键点提取领域的一个重要进步 。 真实世界实验图片
-
-
-