首页
工具导航
归档统计
友链
友文
留言板
关于
更多
打 赏
Search
1
Qt Designer独立安装包Windows版下载指南 | 官方原版一键安装教程
1,392 阅读
2
从PointNet到PointNet++,小白也能看懂的核心思想
949 阅读
3
(可API调用)无需联网即可使用基于深度学习识别的OCR工具Umi-OCR,内置高效率的离线OCR引擎
742 阅读
4
破除玩客云刷机超时难题!Armbian固件直刷包与Amlogic USB Burning工具版本完美搭配指南
724 阅读
5
PyTorch梯度裁剪完全实用指南:原理、场景、优缺点、max_norm值估计方法
491 阅读
开源工具
实用插件
软件开发
机器学习
深度学习
论文阅读
登录
/
注册
找到
1
篇与
实例分割
相关的结果
强化学习实例分割CVPR论文《ColorRL:Reinforced Coloring for End-to-End Instance Segmentation》阅读笔记
论文阅读
# 深度学习
# 强化学习
# 实例分割
# CVPR论文
# ColorRL
# 端到端分割
# 图着色问题
# A3C算法
# Attention U-Net
# 计算机视觉
# 自动化标注
# 多目标识别
# 并行计算
admin
9月2日
0
40
0
2025-09-02
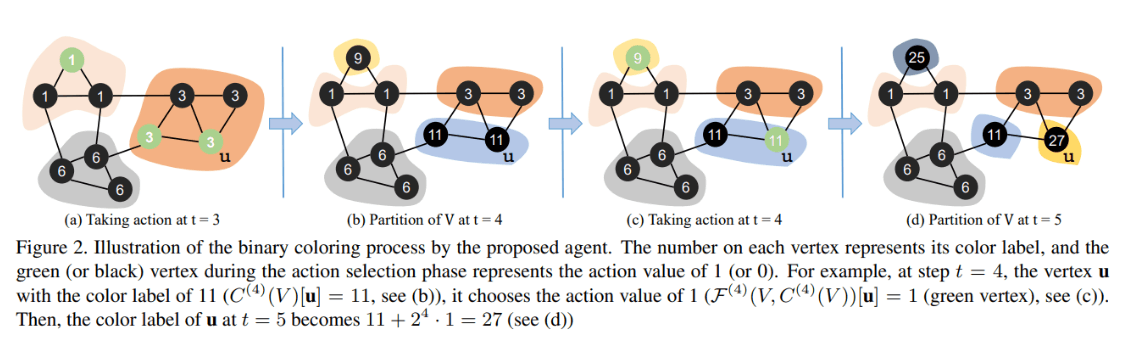
本文深入解读CVPR 2021论文《ColorRL:基于强化学习的端到端实例分割方法》。该研究提出了一种创新的并行实例分割框架ColorRL,将图像分割问题转化为迭代式图着色任务,并借助深度强化学习(A3C算法)训练像素级代理协同工作。通过精心设计的奖励机制鼓励正确合并与分离操作,该方法在CVPPP、KITTI和CREMI等多个数据集上实现了高效且可扩展的分割性能,无需复杂后处理,显著提升了多目标场景下的分割效率。本文系统分析了其核心方法、网络架构与实验结果,为计算机视觉和实例分割研究者提供了深入的技术参考。 论文下载及项目地址 论文下载: Tuan_ColorRL_Reinforced_Coloring_for_End-to-End_Instance_Segmentation_CVPR_2021_paper.pdf Github地址:ColorRL 论文概要 该论文提出了一种新颖的端到端实例分割方法,该方法利用深度强化学习(Deep Reinforcement Learning, DRL)来解决多目标同时分割的问题 。 这篇论文值得被阅读的原因在于"据我们所知,这是第一个基于强化学习的并行运行的端到端实例分割。" To the best of our knowledge, this is the first reinforcement learning-based end-to-end instance segmentation that runs in parallel.论文将实例分割问题转化为一个迭代的图着色问题 。与传统的逐个分割单一对象的方法不同,他们的方法设计了一个由多个像素级代理组成的“着色代理”(coloring agent),这些代理可以并行工作,在顺序的、端到端的过程里区分多个对象 。 迭代图着色图片 核心方法 论文的框架图片 强化学习框架: 该方法使用异步优势行动者-评论家 (A3C) 算法来训练代理 。在每个时间步 t,代理学习如何选择标签的二进制表示中的第 t 位 。每个像素的代理会采取行动(0或1),如果像素属于同一对象,则它们的行动会保持一致,如果属于不同对象,则行动会不同 。 奖励函数: 奖励函数的设计是该方法的关键部分,它旨在鼓励像素级代理进行正确的“分离”(splitting)和“合并”(merging)操作 。该函数包含三个主要组成部分: 奖励前景-背景分割 。 奖励分离操作,即区分不同对象的像素 。 奖励合并操作,即让同一对象的像素具有相同的颜色 。 网络架构: 代理的核心网络使用了 Attention U-Net (AttU) 架构 。输入图像和二值化的颜色图会通过两个不同的路径进入网络,然后进行拼接并由卷积神经网络(CNN)处理 。 实验结果: 作者在三个公开数据集上验证了该方法的性能和可扩展性,分别是: CVPPP (植物表型数据集) KITTI (自动驾驶数据集) CREMI (电子显微镜图像数据集) 该方法在处理多目标图像时表现出高效性,并且不需要复杂的后处理 。与现有的迭代方法相比,特别是在CREMI数据集上,该方法的平均推理时间保持稳定,显示出其优越的可扩展性 。 CVPPP表现图片 电子显微镜图像数据集图片 以“涂鸦”的方式理解 关于本文的实例分割。想象一下,你不是在写代码,而是在教一个机器人成为一个涂鸦高手,它的任务是在一张复杂的图片上把所有不同的物体都分开,并给它们涂上不同的颜色。 传统的“涂鸦”方式 大多数机器人涂鸦师的工作方式是这样的:它们从图像中选择一个物体,比如说一片树叶,然后非常仔细地把它描边和上色。然后,它们再找下一片叶子,重复这个过程,直到所有物体都涂完。这种方法的问题在于,如果图中有成千上万个小物体(比如一片草地),这种逐个涂鸦的方式就会变得非常慢,效率很低 。 强化学习的“涂鸦”方式 这篇论文的作者们想出了一种更聪明、更高效的“涂鸦”方法。他们训练了一个全新的机器人涂鸦师,这个涂鸦师可以同时给多个物体上色。这个机器人不是一次涂一个物体,而是在多个物体上分步、并行地进行涂鸦。具体的过程如下: 第一步:给所有物体上色。机器人首先观察整张图片,然后给所有前景物体都涂上同一种颜色,比如红色。它需要决定哪些像素是前景(比如植物的叶子),哪些是背景(比如泥土和花盆)。 第二步:开始分步“着色”。现在,机器人要开始区分不同的叶子了。它不再使用单一的颜色,而是用一种“二进制”的着色方法。你可以把这个过程想象成,机器人给每个像素赋予一个二进制数,比如 0 或 1。在第一步之后,所有的前景像素可能都获得了 0 这个值。 后续步骤:不断添加“着色位”。在接下来的每一步,机器人都会给每个像素的“二进制颜色”再添加一位。比如,在第二步,它会决定每个像素的第二位颜色是 0 还是 1,这就会把一些物体分成“00”组和“01”组。这个过程会不断迭代下去(比如第三步变成“000”和“001”等)。通过这个过程,本来颜色相同的像素,在经过几步之后就会因为“二进制位”的不同而有了新的颜色,从而被区分开来 。 “奖励”机制:那么机器人怎么知道自己涂得对不对呢?这就是“强化学习”发挥作用的地方了。作者们设计了一个特殊的“奖励”系统: “合并”奖励:如果机器人把属于同一片叶子的像素都涂成了相同的颜色,它就会得到“奖励”。 “分离”奖励:如果机器人成功地把不同叶子上的像素涂上了不同的颜色,它也会得到“奖励”。 这个“奖励”系统就像是你在教一个孩子涂鸦时,如果他涂得好,你就表扬他,如果涂错了,他就会知道这次做得不好。机器人就是通过不断地尝试和接收这些“奖励”来学习如何把所有物体正确地分开和上色 。 这个过程就像一个技艺高超的涂鸦大师,他不是一笔一划地描绘每个小物体,而是通过一种巧妙的分步着色策略,用最少的步骤把整幅画中所有需要区分的物体都完美地着色出来。这个方法使得它在面对大量物体时,依然能够快速、高效地完成任务,特别是在处理像电子显微镜图像中那种密密麻麻的细胞时,其速度优势非常明显 。
智能助理
×
您好,有什么可以帮您从本站内容中寻找答案吗?