首页
工具导航
归档统计
友链
友文
留言板
关于
更多
打 赏
Search
1
Qt Designer独立安装包Windows版下载指南 | 官方原版一键安装教程
1,518 阅读
2
从PointNet到PointNet++,小白也能看懂的核心思想
1,186 阅读
3
破除玩客云刷机超时难题!Armbian固件直刷包与Amlogic USB Burning工具版本完美搭配指南
863 阅读
4
(可API调用)无需联网即可使用基于深度学习识别的OCR工具Umi-OCR,内置高效率的离线OCR引擎
816 阅读
5
Qt 6.9安卓开发环境配置全指南:从零搭建到项目部署(附避坑指南)
571 阅读
开源工具
实用插件
软件开发
机器学习
深度学习
论文阅读
登录
/
注册
找到
1
篇与
PyTorch训练技巧
相关的结果
PyTorch梯度裁剪完全实用指南:原理、场景、优缺点、max_norm值估计方法
深度学习
# PyTorch梯度裁剪
# 梯度裁剪max_norm设置
# torch.nn.utils.clip_grad_norm_
# 深度学习训练稳定技巧
# 梯度爆炸解决方法
# 如何选择max_norm值
# PyTorch训练技巧
# PyTorch中clip_grad_norm_用法
# 梯度裁剪max_norm多少合适
# 深度学习梯度范数控制
# RNN/LSTM训练稳定方法
admin
6月3日
0
550
2
2025-06-03
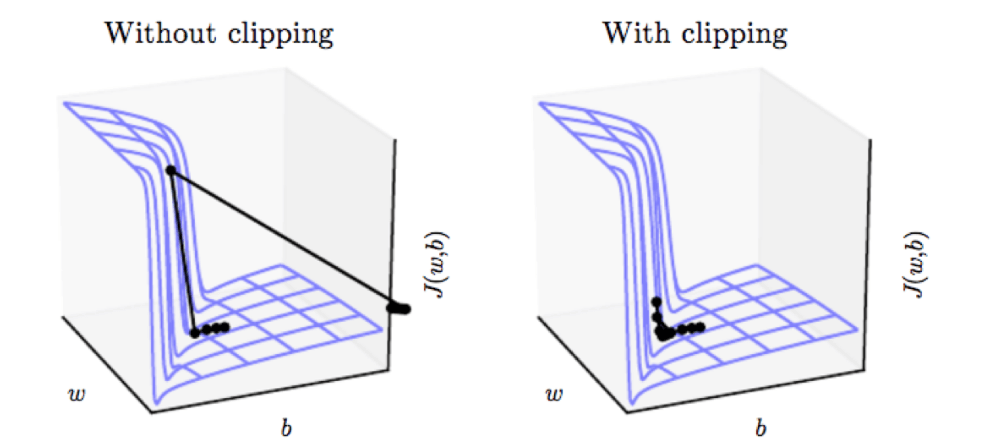
在深度学习模型的训练过程中,经常会遇到一个棘手的问题——梯度爆炸 (Exploding Gradients)。梯度爆炸会导致模型权重更新过大,使得学习过程极其不稳定,甚至导致损失函数变为 NaN (Not a Number),训练无法继续。为了解决这个问题,梯度裁剪 (Gradient Clipping) 应运而生,它是一种简单而有效的技术,能够帮助我们约束梯度的大小,从而稳定训练过程。本文将详细介绍 PyTorch 中梯度裁剪的使用,特别是 torch.nn.utils.clip_grad_norm_ 函数中 max_norm 参数的含义和设置,并探讨如何估计一个合适的 max_norm 值,以及该技巧的优缺点。 什么是梯度裁剪?为什么需要它? 想象一下你在爬山,目标是山谷的最低点(损失函数的最小值)。每一步的大小和方向由梯度决定。如果某一步的梯度特别大(比如你突然踩到了一块非常陡峭的斜坡),你可能会一下子“冲”出很远,甚至越过最低点,或者跑到不相关的区域,导致你离目标越来越远。 在神经网络训练中,特别是在循环神经网络 (RNNs)、长短期记忆网络 (LSTMs)、门控循环单元 (GRUs) 以及包含深层结构的模型中,梯度可能会在反向传播过程中累积变得非常大。这就是梯度爆炸。 典型症状: 损失值突然变成NaN或无穷大 训练过程中损失剧烈震荡 模型参数更新幅度异常巨大 梯度裁剪通过设定一个阈值,当梯度的范数(L2 范数或其他范数)超过这个阈值时,就将其缩放到阈值以内。这样可以防止单次更新步长过大,使得训练过程更加平稳。 梯度裁剪:优雅的解决方案 梯度裁剪就像给你的训练过程装上了"安全带"。它的核心思想很简单:当梯度太大时,按比例缩小它,但保持方向不变。 工作原理 计算所有参数梯度的整体范数(通常是L2范数) 如果范数超过预设阈值max_norm,按比例缩放所有梯度 确保缩放后的范数恰好等于max_norm 数学公式: 如果 total_norm > max_norm: clipped_grad = grad × (max_norm / total_norm) 否则: clipped_grad = grad # 保持不变PyTorch中的基本用法 PyTorch 提供了一个非常方便的函数来实现梯度裁剪:torch.nn.utils.clip_grad_norm_。 import torch import torch.nn as nn # 假设你有一个模型 model = nn.Linear(10, 1) # 假设你有一个优化器 optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 假设你有一些输入和目标 inputs = torch.randn(5, 10) targets = torch.randn(5, 1) # 前向传播 outputs = model(inputs) loss = nn.MSELoss()(outputs, targets) # 反向传播计算梯度 optimizer.zero_grad() loss.backward() # --- 梯度裁剪 --- # 在优化器更新权重之前进行梯度裁剪 max_norm = 20.0 # 这是我们讨论的重点参数 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=max_norm) # ----------------- # 使用裁剪后的梯度更新权重 optimizer.step()torch.nn.utils.clip_grad_norm_ 的关键参数: parameters: 一个可迭代的张量序列,通常是 model.parameters(),包含了模型中所有需要更新梯度的参数。 max_norm (float or int): 梯度的最大范数。如果所有参数的梯度向量拼接后的整体 L2 范数超过这个值,梯度将被重新缩放,使得其范数等于 max_norm。 norm_type (float or int, optional): 指定计算范数的类型。默认为 2,即 L2 范数。也可以使用其他 p-范数。 max_norm=20 的含义: 当设置 max_norm=20 时,意味着在调用 clip_grad_norm_ 后,模型所有参数的梯度向量组合起来计算其 L2 范数,如果这个范数大于 20,那么所有的梯度值都会被按比例缩小,使得最终的 L2 范数恰好等于 20。如果原始范数小于或等于 20,则梯度保持不变。 如何估计 max_norm 的值? 选择一个合适的 max_norm 值至关重要。太小的值可能会过度抑制梯度,减慢学习速度或阻止模型学习到必要的特征;太大的值可能无法有效防止梯度爆炸。 这里提供三种科学的方法: (1)梯度监控法(推荐) def find_optimal_max_norm(model, dataloader, criterion, num_batches=100): """通过监控梯度范数分布来确定最佳max_norm""" gradient_norms = [] for i, (batch_data, batch_labels) in enumerate(dataloader): if i >= num_batches: break model.zero_grad() outputs = model(batch_data) loss = criterion(outputs, batch_labels) loss.backward() # 计算梯度范数 total_norm = 0 for p in model.parameters(): if p.grad is not None: param_norm = p.grad.data.norm(2) total_norm += param_norm.item() ** 2 total_norm = total_norm ** 0.5 gradient_norms.append(total_norm) # 统计分析 import numpy as np norms = np.array(gradient_norms) print(f"梯度范数统计:") print(f" 平均值: {np.mean(norms):.2f}") print(f" 中位数: {np.median(norms):.2f}") print(f" 95分位数: {np.percentile(norms, 95):.2f}") print(f" 最大值: {np.max(norms):.2f}") # 建议的max_norm值 suggested_max_norm = np.percentile(norms, 90) # 90分位数 print(f"建议的max_norm: {suggested_max_norm:.2f}") return suggested_max_norm(2)不同任务的经验值 任务类型推荐max_norm范围说明文本分类0.5 - 2.0较小的网络,梯度相对稳定机器翻译1.0 - 5.0序列到序列模型语言模型0.25 - 1.0大型模型,需要更严格控制图像分类2.0 - 10.0CNN通常梯度较大强化学习0.5 - 2.0策略梯度方法(以上范围仅供参考,具体问题需要具体分析) (3)自适应调整策略 class AdaptiveGradientClipper: def __init__(self, initial_max_norm=1.0, patience=10): self.max_norm = initial_max_norm self.patience = patience self.wait = 0 self.best_loss = float('inf') def clip_and_adjust(self, model, loss): # 执行梯度裁剪 total_norm = torch.nn.utils.clip_grad_norm_( model.parameters(), max_norm=self.max_norm ) # 根据损失调整max_norm if loss < self.best_loss: self.best_loss = loss self.wait = 0 else: self.wait += 1 if self.wait >= self.patience: # 如果损失没有改善,适当放松限制 self.max_norm *= 1.1 self.wait = 0 print(f"调整max_norm为: {self.max_norm:.2f}") return total_norm梯度裁剪的优势与局限 (1)优点 防止梯度爆炸: 这是最主要和最直接的优点。通过限制梯度的大小,可以防止权重更新过大,从而避免损失函数振荡或发散。 提高训练稳定性: 使得训练过程更加平滑,减少了因梯度突变导致的训练中断风险。 可能允许使用更大的学习率: 由于梯度被约束,有时可以尝试使用稍大的学习率而不用担心训练发散,这可能会加速收敛。 有助于处理RNN等深层结构: 在这些网络中,梯度更容易通过长序列或多层传播而爆炸或消失。梯度裁剪对缓解梯度爆炸特别有效。 (2)缺点 引入新的超参数: max_norm (以及 norm_type) 是需要仔细调整的超参数。不合适的选择可能会损害模型性能。 可能扭曲梯度方向: 梯度裁剪(尤其是 clip_grad_norm_)是按比例缩放整个梯度向量,所以它保持了梯度的方向。但 clip_grad_value_ (另一种裁剪方式,对每个梯度分量进行裁剪) 则可能会改变梯度方向。即使是 clip_grad_norm_,如果 max_norm 设置得过小,也可能使得模型无法学到某些需要较大梯度才能驱动的更新。 治标不治本(某种程度上): 梯度裁剪处理的是梯度爆炸的症状,而不是其根本原因(如不良的权重初始化、不合适的激活函数或网络结构设计)。更好的权重初始化方法(如 Xavier, Kaiming 初始化)、使用 ReLU 及其变体、Batch Normalization 或更优化的网络架构(如 ResNet 中的残差连接)可以从根本上减少梯度爆炸的风险。 可能减慢学习速度: 如果 max_norm 设置得过低,会限制模型学习的速度,因为它限制了参数更新的幅度。 总结 梯度裁剪,特别是通过 torch.nn.utils.clip_grad_norm_ 实现的基于范数的裁剪,是深度学习训练工具箱中一个非常有用的技巧。它通过限制梯度的最大范数(例如 max_norm=20)来防止梯度爆炸,从而提高训练的稳定性。 选择合适的 max_norm 值需要结合经验、梯度监控和实验调整。虽然它有一些潜在的缺点,但在许多情况下,梯度裁剪是确保模型训练顺利进行的关键步骤,尤其是在处理复杂和深层网络结构时。记住,它通常与其他稳定训练的技术(如合适的初始化、归一化层等)结合使用,以达到最佳效果。 记住,梯度裁剪不是万能药,但它确实是让你的模型训练"稳如磐石"的重要工具。在下一个项目中试试看,相信你会发现它的价值!
智能助理
×
您好,有什么可以帮您从本站内容中寻找答案吗?