在前面的学习中,我们了解了强化学习的基本概念以及价值学习。今天我们要学习一个新的方法——策略学习(Policy-Based Reinforcement Learning)。如果说之前学的方法是"先学会评估,再决定行动",那么策略学习就是"直接学会怎么行动"。
什么是策略函数?
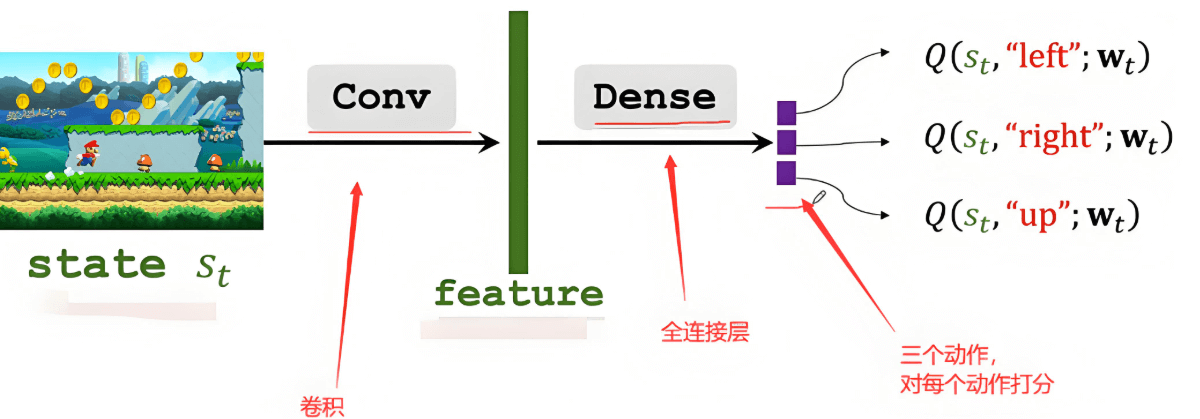
想象你在玩一个游戏,比如超级玛丽。在每个游戏画面(状态)下,你都要做出选择:是往左走、往右走、跳跃,还是按下其他按键?
策略函数π(a | s)就是一个"决策助手",它的工作是:
- 输入:当前的游戏画面(状态s)
- 输出:每个可能动作的概率
比如,当玛丽面前有个坑时,策略函数可能会输出:
- 跳跃:80%的概率
- 往前走:15%的概率
- 往后退:5%的概率
你可能会问:为什么不直接告诉我应该做什么,而要给我一堆概率呢?
这就像生活中的决策一样。即使是相同的情况,有时候我们也会做出不同的选择。在强化学习中,这种"随机性"有几个好处:
- 探索性:可以尝试不同的动作,避免陷入局部最优
- 适应性:在不确定的环境中更灵活
- 连续改进:通过调整概率分布来慢慢学习最优策略
策略学习的基本思想
传统方法可能需要我们手工设计规则,比如"看到敌人就攻击"、"血量低就逃跑"等。但是策略学习的思路是:让神经网络自己学会这些决策规则。
这个过程就像训练一个新手玩家:
- 给他看各种游戏画面
- 让他尝试不同的动作
- 根据结果的好坏来调整他的决策倾向
- 重复这个过程,直到他变成高手
策略梯度算法:让AI学会"从错误中学习"
这里要说明两种情况:离散动作 vs 连续动作
离散动作:就像游戏手柄的按键,要么按下,要么不按。比如:
- 向上、向下、向左、向右
- 攻击、防御、使用道具
连续动作:就像方向盘的转向,可以有无数种角度。比如:
- 汽车转向的角度(0度到360度之间的任意值)
- 机器人手臂的移动距离
两种动作类型的区别主要在于策略函数的输出形式:
- 离散动作:输出每个动作的概率,比如[上:0.2, 下:0.3, 左:0.4, 右:0.1]
- 连续动作:输出分布的参数,比如正态分布的均值μ=1.5和标准差σ=0.8
但无论哪种类型,都使用相同的学习框架:采样→执行→评估→学习。
不同类型的动作需要用不同的数学方法来处理,但核心思想是一样的。蒙特卡洛估计本身与动作类型无关,它是一种估计期望值的方法,无论是离散动作还是连续动作都可以使用。
策略梯度算法的工作流程

让我们用一个具体的例子来理解整个流程。假设我们在训练一个AI玩贪吃蛇游戏:
(1)获得观测状态s_t
- AI看到当前的游戏画面:蛇的位置、食物的位置、墙壁的位置等
- 就像你玩游戏时观察屏幕一样
(2)从策略函数中随机采样动作a_t
神经网络分析画面,给出四个方向的概率,比如:
- 上:10%
- 下:20%
- 左:30%
- 右:40%
- AI根据这些概率随机选择一个动作,比如选择了"右"
(3)计算价值函数的值 这一步是评估"这个动作到底好不好"。有两种方法:
方法1:完整记录法
- 把整个游戏过程都记录下来
- 游戏结束后,看最终得分
- 如果得分高,说明这局的所有动作都不错
- 就像考试后根据总分来评价每个题目的答题策略
方法2:价值网络评估法
- 训练另一个神经网络来预测"当前状态有多好"
- 不用等游戏结束,立即就能知道动作的好坏
- 就像有个经验丰富的教练在旁边实时指导
(4)对价值网络进行求导
- 这是计算"应该往哪个方向调整"的数学步骤
- 就像确定"应该增加还是减少某个动作的概率"
(5)近似计算策略梯度
- 梯度告诉我们"参数应该怎么调整"
- 如果某个动作导致了好结果,就增加它的概率
- 如果某个动作导致了坏结果,就降低它的概率
(6)更新网络的参数
- 根据计算出的梯度来调整神经网络
- 让AI在下一次遇到类似情况时,做出更好的选择
为什么是梯度上升而不是下降?
在机器学习中,我们通常听到"梯度下降",为什么到强化学习这里是"梯度上升"呢?
梯度下降:用来最小化损失(比如预测错误)
梯度上升:用来最大化奖励(比如游戏得分)
想象你在爬山:
- 如果你想到达山谷(最小化高度),你会沿着下坡的方向走 → 梯度下降
- 如果你想到达山顶(最大化高度),你会沿着上坡的方向走 → 梯度上升
在强化学习中,我们的目标是最大化累积奖励,所以我们要"往山顶爬",因此使用梯度上升。

小结
策略学习是强化学习中的一个重要分支,它的核心思想是直接学习决策策略。通过神经网络来拟合策略函数,使用策略梯度算法来优化参数,最终让AI学会在不同状态下做出最优的动作选择。
虽然这个方法听起来复杂,但其实就是在模拟人类学习的过程:观察环境、尝试行动、评估结果、调整策略。理解了这个基本思路,你就掌握了策略学习的精髓。
在下一篇笔记中,我们将学习更多具体的策略学习算法,比如REINFORCE、Actor-Critic等。这些都是基于今天学到的基础概念发展而来的。