找到
2
篇与
Q-learning
相关的结果
-

-
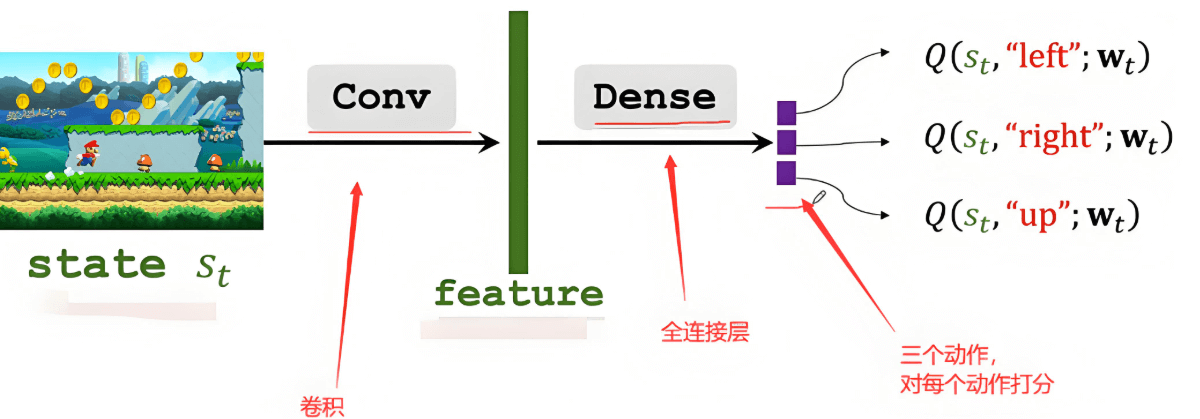
强化学习小白入门笔记1:必须要理解的核心概念 本文系统介绍了强化学习的核心基础概念,包括智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)等关键术语。通过生活化的找路例子,详细解释了强化学习的工作原理及其在人工智能领域的应用价值。文章还阐述了状态转移、策略、回报、价值函数等进阶概念,为工科研究生和初学者提供了全面的强化学习入门指南,为后续学习Q-learning、Policy Gradient等算法奠定坚实基础。 什么是强化学习? 在开始介绍具体概念之前,让我们先用一个生活化的例子来理解强化学习的本质。 想象一下你刚刚搬到一个新城市,需要找到从家到实验室的最佳路线。一开始你对这个城市一无所知,只能凭直觉选择方向。走错路时你会感到沮丧(负奖励),找到捷径时你会感到高兴(正奖励)。经过多次尝试后,你逐渐学会了如何在不同的交通状况下选择最优路线。这个过程就是强化学习的核心思想:通过与环境互动,根据得到的反馈来改进决策策略。 核心概念详解 (1) Agent(智能体)和Environment(环境) Agent(智能体)是强化学习中的"学习者"和"决策者"。在上面的例子中,你就是Agent。在实际应用中,Agent可以是机器人、游戏AI、推荐系统等任何需要做出决策的系统。 Environment(环境)则是Agent所处的外部世界,包含了Agent需要应对的所有外部因素。继续用找路的例子,城市的道路网络、交通信号灯、其他车辆和行人构成了你的环境。 这两者的关系是互动的:Agent观察环境,在环境中采取行动,环境则给予Agent反馈。 (2) State(状态) State(状态)是对环境当前情况的完整描述。它包含了Agent做出决策所需的所有相关信息。 在找路例子中,状态可能包括:当前位置、目的地、时间、天气、交通拥堵情况等。在下棋游戏中,状态就是当前的棋盘布局。在机器人控制中,状态可能包括机器人的位置、速度、传感器读数等。 需要注意的是,状态应该具有马尔可夫性质,即"未来只依赖于现在,而不依赖于过去"。简单来说,只要知道当前状态,就能对未来做出最好的决策,不需要知道是如何到达当前状态的。 (3) Action(动作) Action(动作)是Agent在给定状态下可以执行的所有可能操作。 在找路例子中,你的动作可能是"直行"、"左转"、"右转"、"掉头"等。在下棋中,动作就是在棋盘上的合法落子位置。在机器人控制中,动作可能是各种运动指令。 动作可以是离散的(如选择特定的路径),也可以是连续的(如设置具体的速度值)。 (4) Reward(奖励) Reward(奖励)是环境对Agent动作的即时反馈,用一个数值来表示动作的好坏。 这是强化学习中最关键的概念之一,因为Agent的目标就是最大化累积奖励。在找路例子中,快速到达目的地可能得到正奖励,走错路或遇到堵车得到负奖励。在游戏中,获胜得到正奖励,失败得到负奖励。 奖励的设计需要非常小心,因为Agent会严格按照奖励信号来优化自己的行为。如果奖励设计不当,可能会导致Agent学会"钻空子"而不是解决真正的问题。 (5) State Transition(状态转移) State Transition(状态转移)描述了环境如何从一个状态变化到另一个状态。当Agent在状态s下执行动作a时,环境会转移到新状态s',这个过程可能是确定的,也可能是随机的。 在找路例子中,如果你在十字路口选择左转,确定性的状态转移会让你到达左边的街道。但如果考虑到突发的交通事故或道路施工,状态转移就可能带有随机性。 (6) Policy(策略) Policy(策略)是Agent的"行动指南",它定义了在每个状态下应该采取什么动作。策略通常用π来表示。 策略可以是确定性的(在给定状态下总是执行同一个动作)或随机性的(根据概率分布选择动作)。在找路例子中,你的策略可能是"在工作日早高峰时避开主干道,选择小路"。 (7) Return(回报) Return(回报)是从某个时刻开始的累积奖励。与即时奖励不同,回报考虑的是长期收益。 假设Agent在时刻t得到奖励序列:r_{t+1}, r_{t+2}, r_{t+3}, ...,那么从时刻t开始的回报通常定义为: G_t = r_{t+1} + γr_{t+2} + γ²r_{t+3} + ... 其中γ(gamma)是折扣因子(0 ≤ γ ≤ 1),用来平衡即时奖励和未来奖励的重要性。 γ越接近1,Agent越重视未来奖励;γ越接近0,Agent越重视即时奖励。 (8) Value Function(价值函数) 价值函数评估状态或动作的"好坏程度",是强化学习中的核心概念。 State-value Function(状态价值函数)V^π(s)表示在状态s下,遵循策略π能够获得的期望回报。简单来说,它回答了"在这个状态下,按照当前策略行动,我能期望获得多少总奖励?" 在找路例子中,如果某个路口的状态价值很高,说明从这个路口出发,按照你当前的策略,很可能快速到达目的地。 (9) Action-value Function(动作价值函数) Action-value Function(动作价值函数)Q^π(s,a)表示在状态s下执行动作a,然后遵循策略π的期望回报。它回答了"在当前状态下,如果我执行这个特定动作,然后按照策略继续行动,我能期望获得多少总奖励?" Q函数比V函数提供了更细粒度的信息,因为它不仅告诉你状态的价值,还告诉你在该状态下不同动作的价值。 (10) Optimal Action-value Function(最优动作价值函数) Optimal Action-value Function(最优动作价值函数), Q*(s,a)表示在状态s下执行动作a,然后遵循最优策略的期望回报。这是在给定状态和动作下能够获得的最大可能回报。 强化学习的另一个主要目标就是学习到最优Q函数Q,因为一旦有了Q,就可以通过选择使Q*(s,a)最大的动作a来获得最优策略。 迭代优化图片 概念的关系 Environment ←→ Agent ↓ ↓ State → Action ↓ ↓ Reward ← Policy ↓ Return ↓ Value FunctionsAgent观察Environment的State,根据Policy选择Action,Environment给出Reward并转移到新State。通过积累Reward形成Return,进而计算Value Functions来评估Policy的好坏,最终优化Policy。 训练是学什么? 强化学习的核心目标是: 学习最优策略π*:知道在每个状态下应该采取什么动作 学习最优Q函数Q*:知道在每个状态下,每个动作的真实价值 这两个目标是相互关联的。如果我们有了最优Q函数,就可以通过贪婪策略(即选择Q值最大的动作)得到最优策略。反之,如果我们有了最优策略,也可以通过该策略评估出最优Q函数。 小结 强化学习是一个让智能体通过与环境互动来学习最优决策策略的框架。理解这些核心概念是深入学习强化学习算法的基础: Agent和Environment构成了学习的基本框架 State、Action、Reward是互动的基本要素 Policy是我们要学习的决策规则 Value Functions帮助我们评估决策的好坏 Return连接了即时奖励和长期目标 在后续的学习中,你会发现所有的强化学习算法,无论是Q-learning、Policy Gradient还是Actor-Critic,都是围绕着如何更好地学习π*或Q*而设计的。掌握了这些基础概念,你就为进一步学习具体算法打下了坚实的基础。