找到
10
篇与
深度学习
相关的结果
-

-
强化学习小白入门笔记3:深入理解时序差分学习的原理和应用Temporal Difference Learning 时序差分学习(Temporal Difference Learning,简称TD学习)是强化学习中最重要的概念之一,也是现代强化学习算法的核心基础。如果说强化学习是一栋大厦,那么TD学习就是这栋大厦的地基。本文主要是面向初学者,深入理解这个看似复杂但实际上非常直观的学习方法。 学习的本质是什么? 在开始之前,让我们思考一个问题:人类是如何学习的? 想象你第一次学开车。你不会等到考完驾照才开始总结经验,而是在每次练车过程中不断调整: 刚开始转弯时总是转得太急,几次练习后学会了提前减速 停车时总是停不准,通过观察后视镜的反馈不断改进 每次小的改进都基于当时的反馈,而不是等到所有练习结束 这就是TD学习的核心思想:用当前的经验来改进我们的预测,而不是等到所有事情结束。 TD学习的核心思想 时序差分这个名字听起来很学术,但概念其实很简单: 时序:涉及时间序列,我们在不同时刻有不同的预测 差分:比较不同时刻预测之间的差异 TD学习的核心就是:用"更准确的后续预测"来改进"当前的预测"。简单来说就是“有事及时处理”。 生活化的类比:天气预报学习 假设你想学会预测天气,但你不是气象专家,只能通过观察来学习。 传统方法(等到月底再学习): 月初预测:这个月平均气温25度 等到月底:实际平均气温27度 月底学习:调整下个月的预测策略 TD方法(每天都学习): 1号预测:这个月平均25度,明天26度 2号实际:昨天确实26度,今天预测这个月平均25.1度,明天27度 发现:昨天预测月平均25度,但今天的新信息(实际26度+预测明天27度)暗示月平均可能更高 立即调整:把对这个月平均气温的预测从25度调到25.1度 关键洞察:我们不需要等到月底,每天的新信息都能帮助我们改进长期预测! 天气预报图片 TD学习的数学原理 TD学习的核心公式看起来是这样的: V(s) ← V(s) + α × [r + γ × V(s') - V(s)]各部分含义: V(s):我们对状态s的价值估计 α:学习率(0-1之间,比如0.1) r:在状态s执行动作后获得的即时奖励 γ:折扣因子(0-1之间,比如0.9) V(s'):我们对下一状态s'的价值估计 核心思想:新估计 = 旧估计 + 学习率 × (更好的估计 - 旧估计) 公式中的 [r + γ × V(s') - V(s)] 被称为TD误差(TD Error),这是TD学习的核心: r + γ × V(s') :基于当前经验的"更好估计" r:我们实际获得的奖励 γ × V(s'):未来价值的折扣估计 V(s):我们之前的估计 TD误差:两者的差值,告诉我们估计的准确程度 TD误差的含义: 如果TD误差 > 0:我们低估了当前状态的价值,应该调高 如果TD误差 < 0:我们高估了当前状态的价值,应该调低 如果TD误差 = 0:我们的估计刚好准确 机器人学习走迷宫 问题设置 想象一个简单的3×3迷宫: [S][ ][G] [ ][#][ ] [ ][ ][ ]S:起始位置 G:目标位置(奖励+10) \#:障碍物 空格:可以通行(每步奖励-1) 学习目标:学会评估每个位置的价值(从该位置到达目标的期望累计奖励) 初始状态 刚开始时,机器人对所有位置的价值估计都是0: 价值估计表: V(S) = 0, V(G) = 10, V(其他位置) = 0 学习率 α = 0.1 折扣因子 γ = 0.9第一次探索过程 步骤1:从S向右移动 当前状态:S,价值估计V(S) = 0 执行动作:向右 获得奖励:r = -1(移动成本) 到达新状态:中间位置,价值估计V(中间) = 0 TD更新: TD误差 = r + γ × V(中间) - V(S) = -1 + 0.9 × 0 - 0 = -1 更新V(S) = V(S) + α × TD误差 = 0 + 0.1 × (-1) = -0.1步骤2:从中间向右移动到目标 当前状态:中间,价值估计V(中间) = 0 执行动作:向右 获得奖励:r = 10(到达目标) 到达新状态:目标G,价值估计V(G) = 10 TD更新: TD误差 = r + γ × V(G) - V(中间) = 10 + 0.9 × 10 - 0 = 19 更新V(中间) = V(中间) + α × TD误差 = 0 + 0.1 × 19 = 1.9第二次探索过程 现在价值估计表变成了: V(S) = -0.1, V(中间) = 1.9, V(G) = 10再次从S向右移动: TD误差 = r + γ × V(中间) - V(S) = -1 + 0.9 × 1.9 - (-0.1) = -1 + 1.71 + 0.1 = 0.81 更新V(S) = -0.1 + 0.1 × 0.81 = -0.019学习过程的直观理解 通过这个例子,我们可以看到: 即时学习:每走一步都更新价值估计,不用等到到达终点 信息传播:目标的高价值(+10)逐渐"传播"到前面的状态 渐进改进:每次更新都让估计更准确一点点 最终收敛:经过足够多的探索,所有状态的价值估计会趋于真实值 TD学习的优势与局限 主要优势 模型无关:不需要知道环境的转移概率和奖励函数 在线学习:可以在与环境交互过程中实时学习 内存高效:不需要存储完整的轨迹历史 快速响应:能够快速适应环境的变化 理论保证:在一定条件下保证收敛到最优解 主要局限 探索问题:如何平衡探索未知状态和利用已知信息 函数近似:在大状态空间中需要函数近似,可能不稳定 参数调整:学习率、折扣因子等参数需要仔细调整 收敛速度:虽然每步都学习,但总体收敛可能较慢

-
-
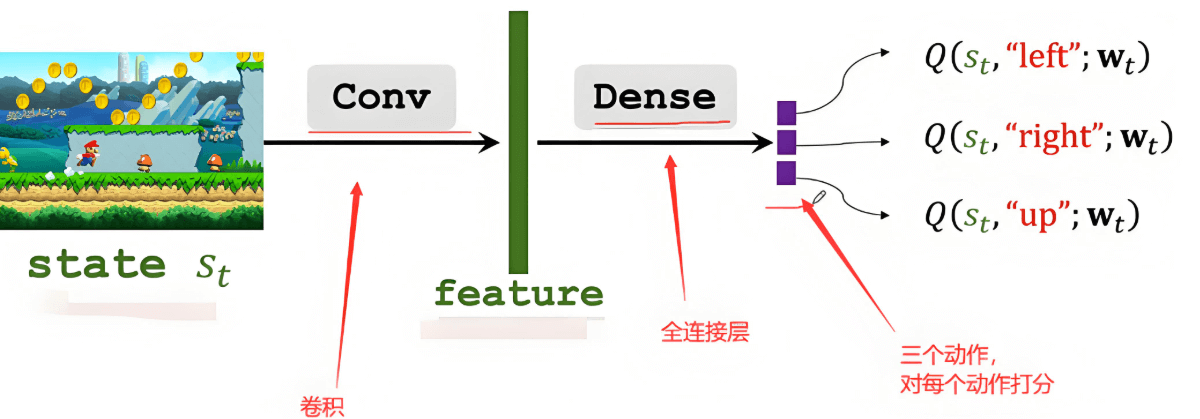
强化学习小白入门笔记1:必须要理解的核心概念 本文系统介绍了强化学习的核心基础概念,包括智能体(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)等关键术语。通过生活化的找路例子,详细解释了强化学习的工作原理及其在人工智能领域的应用价值。文章还阐述了状态转移、策略、回报、价值函数等进阶概念,为工科研究生和初学者提供了全面的强化学习入门指南,为后续学习Q-learning、Policy Gradient等算法奠定坚实基础。 什么是强化学习? 在开始介绍具体概念之前,让我们先用一个生活化的例子来理解强化学习的本质。 想象一下你刚刚搬到一个新城市,需要找到从家到实验室的最佳路线。一开始你对这个城市一无所知,只能凭直觉选择方向。走错路时你会感到沮丧(负奖励),找到捷径时你会感到高兴(正奖励)。经过多次尝试后,你逐渐学会了如何在不同的交通状况下选择最优路线。这个过程就是强化学习的核心思想:通过与环境互动,根据得到的反馈来改进决策策略。 核心概念详解 (1) Agent(智能体)和Environment(环境) Agent(智能体)是强化学习中的"学习者"和"决策者"。在上面的例子中,你就是Agent。在实际应用中,Agent可以是机器人、游戏AI、推荐系统等任何需要做出决策的系统。 Environment(环境)则是Agent所处的外部世界,包含了Agent需要应对的所有外部因素。继续用找路的例子,城市的道路网络、交通信号灯、其他车辆和行人构成了你的环境。 这两者的关系是互动的:Agent观察环境,在环境中采取行动,环境则给予Agent反馈。 (2) State(状态) State(状态)是对环境当前情况的完整描述。它包含了Agent做出决策所需的所有相关信息。 在找路例子中,状态可能包括:当前位置、目的地、时间、天气、交通拥堵情况等。在下棋游戏中,状态就是当前的棋盘布局。在机器人控制中,状态可能包括机器人的位置、速度、传感器读数等。 需要注意的是,状态应该具有马尔可夫性质,即"未来只依赖于现在,而不依赖于过去"。简单来说,只要知道当前状态,就能对未来做出最好的决策,不需要知道是如何到达当前状态的。 (3) Action(动作) Action(动作)是Agent在给定状态下可以执行的所有可能操作。 在找路例子中,你的动作可能是"直行"、"左转"、"右转"、"掉头"等。在下棋中,动作就是在棋盘上的合法落子位置。在机器人控制中,动作可能是各种运动指令。 动作可以是离散的(如选择特定的路径),也可以是连续的(如设置具体的速度值)。 (4) Reward(奖励) Reward(奖励)是环境对Agent动作的即时反馈,用一个数值来表示动作的好坏。 这是强化学习中最关键的概念之一,因为Agent的目标就是最大化累积奖励。在找路例子中,快速到达目的地可能得到正奖励,走错路或遇到堵车得到负奖励。在游戏中,获胜得到正奖励,失败得到负奖励。 奖励的设计需要非常小心,因为Agent会严格按照奖励信号来优化自己的行为。如果奖励设计不当,可能会导致Agent学会"钻空子"而不是解决真正的问题。 (5) State Transition(状态转移) State Transition(状态转移)描述了环境如何从一个状态变化到另一个状态。当Agent在状态s下执行动作a时,环境会转移到新状态s',这个过程可能是确定的,也可能是随机的。 在找路例子中,如果你在十字路口选择左转,确定性的状态转移会让你到达左边的街道。但如果考虑到突发的交通事故或道路施工,状态转移就可能带有随机性。 (6) Policy(策略) Policy(策略)是Agent的"行动指南",它定义了在每个状态下应该采取什么动作。策略通常用π来表示。 策略可以是确定性的(在给定状态下总是执行同一个动作)或随机性的(根据概率分布选择动作)。在找路例子中,你的策略可能是"在工作日早高峰时避开主干道,选择小路"。 (7) Return(回报) Return(回报)是从某个时刻开始的累积奖励。与即时奖励不同,回报考虑的是长期收益。 假设Agent在时刻t得到奖励序列:r_{t+1}, r_{t+2}, r_{t+3}, ...,那么从时刻t开始的回报通常定义为: G_t = r_{t+1} + γr_{t+2} + γ²r_{t+3} + ... 其中γ(gamma)是折扣因子(0 ≤ γ ≤ 1),用来平衡即时奖励和未来奖励的重要性。 γ越接近1,Agent越重视未来奖励;γ越接近0,Agent越重视即时奖励。 (8) Value Function(价值函数) 价值函数评估状态或动作的"好坏程度",是强化学习中的核心概念。 State-value Function(状态价值函数)V^π(s)表示在状态s下,遵循策略π能够获得的期望回报。简单来说,它回答了"在这个状态下,按照当前策略行动,我能期望获得多少总奖励?" 在找路例子中,如果某个路口的状态价值很高,说明从这个路口出发,按照你当前的策略,很可能快速到达目的地。 (9) Action-value Function(动作价值函数) Action-value Function(动作价值函数)Q^π(s,a)表示在状态s下执行动作a,然后遵循策略π的期望回报。它回答了"在当前状态下,如果我执行这个特定动作,然后按照策略继续行动,我能期望获得多少总奖励?" Q函数比V函数提供了更细粒度的信息,因为它不仅告诉你状态的价值,还告诉你在该状态下不同动作的价值。 (10) Optimal Action-value Function(最优动作价值函数) Optimal Action-value Function(最优动作价值函数), Q*(s,a)表示在状态s下执行动作a,然后遵循最优策略的期望回报。这是在给定状态和动作下能够获得的最大可能回报。 强化学习的另一个主要目标就是学习到最优Q函数Q,因为一旦有了Q,就可以通过选择使Q*(s,a)最大的动作a来获得最优策略。 迭代优化图片 概念的关系 Environment ←→ Agent ↓ ↓ State → Action ↓ ↓ Reward ← Policy ↓ Return ↓ Value FunctionsAgent观察Environment的State,根据Policy选择Action,Environment给出Reward并转移到新State。通过积累Reward形成Return,进而计算Value Functions来评估Policy的好坏,最终优化Policy。 训练是学什么? 强化学习的核心目标是: 学习最优策略π*:知道在每个状态下应该采取什么动作 学习最优Q函数Q*:知道在每个状态下,每个动作的真实价值 这两个目标是相互关联的。如果我们有了最优Q函数,就可以通过贪婪策略(即选择Q值最大的动作)得到最优策略。反之,如果我们有了最优策略,也可以通过该策略评估出最优Q函数。 小结 强化学习是一个让智能体通过与环境互动来学习最优决策策略的框架。理解这些核心概念是深入学习强化学习算法的基础: Agent和Environment构成了学习的基本框架 State、Action、Reward是互动的基本要素 Policy是我们要学习的决策规则 Value Functions帮助我们评估决策的好坏 Return连接了即时奖励和长期目标 在后续的学习中,你会发现所有的强化学习算法,无论是Q-learning、Policy Gradient还是Actor-Critic,都是围绕着如何更好地学习π*或Q*而设计的。掌握了这些基础概念,你就为进一步学习具体算法打下了坚实的基础。
-
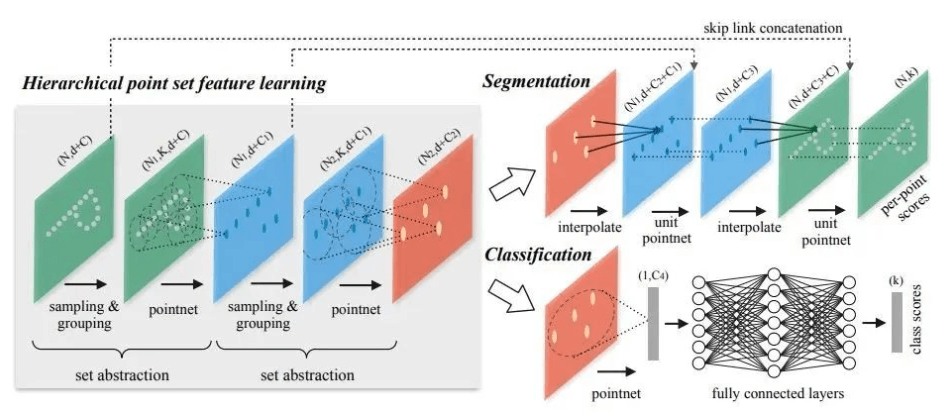
从PointNet到PointNet++,小白也能看懂的核心思想 欢迎来到小陶的技术博客。如果你和我一样,是一名刚刚踏入三维点云处理世界的新手,你一定听说过 PointNet 和 PointNet++ 这两个大名鼎鼎的模型。它们就像是3D视觉领域的“开山鼻祖”,理解了它们,学习之路会顺畅很多。 今天,我也是根据自己看的一些别的博客资料以及B站视频,梳理这两个模型的“来龙去脉”和核心思想。 为什么要有点云模型?传统方法不行吗? 深入了解PointNet之前,先问一个问题:我们熟悉的二维图片处理方法(比如CNN,卷积神经网络)为什么不能直接用在三维点云上? 想象一下,一张图片就像一个整齐的棋盘,每个像素都有自己固定的位置。CNN的“卷积核”就像一个小窗口,在棋盘上规律地滑来滑去,提取特征。但点云完全不同,它就像一把随意撒在空中的沙子。它有两大特性,让CNN直接“水土不服”: 无序性 (Unordered): 一堆点,你先看A点再看B点,和我先看B点再看A点,描述的应该是同一个物体。点的顺序不应该影响最终结果。但对于传统神经网络,输入顺序变了,结果可能就天差地别。 空间结构性 (Sparsity & Irregularity): 点云不像像素那样均匀分布,它可能在某些地方密集(比如物体的棱角),在某些地方稀疏(比如一个平面)。你没法像CNN那样用一个固定大小的窗口去“滑动”。 为了解决这两个核心痛点,PointNet应运而生。 PointNet:简单粗暴的“大力出奇迹” PointNet是第一个直接处理原始点云的深度学习模型,它的想法堪称“天才般的简单”。 核心思想:如何解决“无序性”? PointNet的作者想:我需要找到一种方法,无论点的顺序怎么打乱,我最后得到的特征都是一样的。这种特性在数学上叫做“对称函数” (Symmetric Function)。 常见的对称函数有哪些? 求和 (Summation): a+b+c 和 c+b+a 的结果是一样的。 求平均 (Average): (a+b+c)/3 和 (c+b+a)/3 的结果是一样的。 求最大值 (Max-Pooling): max(a, b, c) 和 max(c, b, a) 的结果是一样的。 PointNet最终选择了 Max-Pooling(最大池化) 作为它的核心对称函数。 PointNet工作流程(三步走): 独立特征提取: 输入是一堆点的坐标(一个大小为 N x 3 的矩阵,N是点的数量,3是XYZ坐标)。 PointNet对 每一个点 单独进行特征学习,把它从3维映射到更高维度的空间(比如1024维)。你可以把它想象成给每个点“画像”,让它的信息更丰富。这一步是通过几个共享参数的多层感知机(MLP)完成的。 全局特征聚合(关键一步): 现在我们有N个1024维的特征向量了。 PointNet在这些特征向量的 每一个维度上 做一次Max-Pooling。也就是说,在第一个维度上,从N个点中选出最大值;在第二个维度上,也选出最大值……以此类推。 做完之后,N个点的特征就被“压”成了一个1024维的 全局特征向量。这个向量代表了整个点云的“样子”。因为Max-Pooling是无序的,所以无论输入点的顺序如何,这个全局特征都是不变的! 输出结果: 最后,用这个全局特征向量去做具体的任务,比如接一个分类器判断这个点云是什么物体(桌子?椅子?),或者做一个分割器判断每个点属于物体的哪个部分。 # PointNet用于分类任务的伪代码 function pointnet_classification(point_cloud): # point_cloud 是一组N个点 {p1, p2, ..., pN} # 1. 对每个点独立应用MLP,提取高维特征 point_features = [] for point in point_cloud: # 比如把 (x,y,z) 变成一个1024维的特征 feature = MLP(point) point_features.append(feature) # 2. 使用对称函数(Max-Pooling)聚合所有点的特征 # 这是保证顺序不变性的核心! # 从 [N, 1024] 的特征矩阵,池化成 [1, 1024] 的全局特征 global_feature = max_pool(point_features) # 3. 使用最后的MLP进行分类 prediction_scores = MLP(global_feature) return prediction_scoresPointNet虽然开创了历史,但它的方法太“粗暴”了。它通过Max-Pooling把所有点的信息都揉成一团,形成一个全局特征。这导致它 无法感知局部细节。 打个比方,PointNet能认出这是一辆车,但它很难分清车轮和车灯的区别,因为它把所有点的特征“一视同仁”地混合了,丢失了点与点之间的邻里关系和局部几何结构。 PointNet++:从“全局”到“局部”的精细化升级 为了解决PointNet丢失局部结构的问题,PointNet++被提了出来。它的核心思想非常像我们熟悉的CNN,那就是——层次化特征提取 (Hierarchical Feature Learning)。 核心思想:先局部,再整体 如果说PointNet是“一口吃成个胖子”,那PointNet++就是“细嚼慢咽”。它不再直接对所有点进行粗暴的全局池化,而是: 分片 (Partition): 在点云中选择几个“中心点”。 分组 (Grouping): 以每个中心点为核心,在周围画一个“圈”(比如一个球形半径内),把邻近的点组织成一个小局部区域。 小PointNet提取局部特征: 对每一个小局部区域,使用一个迷你的PointNet来提取这个区域的局部特征。 迭代升级: 不断重复以上过程。上一层提取的局部特征,会成为下一层分组和提取的输入。这样一来,网络就能从非常小的局部细节(比如桌子腿的棱角),逐渐学习到更大范围的特征(整个桌子腿),最后再到全局特征(整张桌子)。 这个核心组件,PointNet++称之为 集合抽象层 (Set Abstraction Layer)。 一个Set Abstraction Layer的伪代码: # PointNet++ 中一个 Set Abstraction 层的伪代码 function set_abstraction_layer(points, features): # points是输入的点集,features是这些点对应的特征 # 1. 采样层:用最远点采样(FPS)选出一些中心点 centroids = farthest_point_sampling(points) # 2. 分组层:为每个中心点,找到它的邻居点 groups = [] for c in centroids: # 比如在半径r内找邻居 (Ball Query) neighbors = find_neighbors_in_radius(c, points, radius) groups.append(neighbors) # 3. PointNet层:对每个组用一个“迷你PointNet”来提取局部特征 new_features = [] for group in groups: # 注意:在送入迷你PointNet前,会先将邻居点坐标归一化到局部坐标系 local_feature = mini_pointnet_module(group) new_features.append(local_feature) # 输出:新的点(中心点)和它们对应的更高级的特征 return centroids, new_features通过堆叠多个这样的set_abstraction_layer,PointNet++就能像CNN一样,一层层地扩大感受野,从点到线,从线到面,最终理解整个三维物体的复杂结构。 如果还没理解,我们来做一个最后的比喻: PointNet: 就像全国海选。所有选手(点)都来到一个大舞台上,评委(Max-Pooling)只看一眼,选出最亮眼的那一个(最大特征值)来代表所有人。这个方法简单高效,能快速得到一个总体印象,但忽略了选手们在各自地区(局部)的特色。 PointNet++: 就像分级选举。先在每个村里选出村代表(第一层局部特征),然后村代表们再开会选出镇代表(第二层更大范围的特征),镇代表再选出县代表……最后选出国家主席(最终的全局特征)。这个过程更复杂,但能充分保留从基层到高层的各级信息,对情况的把握更精细。 特性PointNetPointNet++核心思想对称函数(Max-Pooling)处理无序性层次化特征提取结构感知仅有全局特征,无局部结构信息有局部结构信息,从局部到全局处理方式一步到位,简单粗暴逐层抽象,精细复杂适用场景简单的分类任务,对细节要求不高的场景分割、复杂场景理解等需要局部信息的任务比喻全国海选分级选举写在最后 PointNet和PointNet++是3D点云深度学习的基石。虽然现在已经有了更多更复杂的模型,但它们的思想——如何解决无序性、如何学习局部和全局特征——依然在影响着后续的研究。 对于初学者来说,不必急于深究代码的每一个细节,最重要的是理解其背后的思想。
-
-
-
-
【Matlab深度学习实战】99.16%高精度交通标志识别系统开发:开源数据集优化+ResNet50迁移学习+App设计全解析(含工程源码) 本文详解基于Matlab R2024b的交通标志智能识别系统开发全流程。通过重构消除开源数据集污染与不均衡问题,采用ResNet50迁移学习技术实现50+类别99.16%超高识别准确率。内含完整数据清洗方案、分层抽样策略、Adam优化器参数配置,以及Matlab App Designer开发的交互式识别系统。提供经优化的开源数据集、带注释的工程源码及预训练模型,特别包含GPU加速训练技巧、混淆矩阵可视化方法、F1-score评估体系,助力开发者快速复现论文级实验结果,掌握工业级模型部署技巧。 效果视频 训练数据 前面小栈发布了一个开源数据集:【中国交通标志数据集TSRD下载】上海交大网盘高速下载+58类6164张标注图像 但是小栈发现开源的数据集存在一些问题,比如数据污染、数据不均衡的问题,会导致模型不稳定和动荡,因此,小栈对数据集进行了重新的编排。小栈润色后的数据集会和源码一起进行发布和下载。 软件环境 小栈使用的Matlab是R2024b,如果需要本套资料,建议与小栈保持一致哦,如果可能出现各种不兼容或者报错。 训练说明 下面对代码进行简单的说明,如果有需要,可以直接使用到您的报告中: 首先设定数据集路径及训练超参数,明确使用224×224像素的RGB输入格式。通过imageDatastore加载图像数据并自动继承文件夹名称作为类别标签,采用自定义预处理函数统一调整图像尺寸并确保三通道格式。为保证模型泛化能力,以分层抽样方式将数据集按8:2划分为训练集与测试集,并验证两者标签的一致性,避免测试集出现未知类别。最终统计显示共包含N个交通标志类别,训练集与测试集样本量分别为X和Y。 通过augmentedImageDatastore实现实时增强处理。网络架构方面,加载预训练的ResNet50模型后,移除原1000类分类层,替换为与当前任务类别数匹配的全连接层(设置较高10倍学习率因子加速训练),配合新的softmax和分类输出层完成结构调整。 采用分阶段训练机制:首先冻结所有卷积层的权重学习率因子(设为0),保持底层特征提取能力不变,仅训练新添加的分类层。通过layerGraph遍历替换所有卷积层的参数更新属性,确保特征提取部分权重冻结。网络分析确认结构调整正确后,配置Adam优化器(初始学习率0.001)、64批次大小及15轮次训练方案,每30批次验证一次测试集准确率,利用GPU加速训练过程。 训练显示损失曲线和准确率变化,动态保存最佳模型参数。完成训练后,模型在测试集上执行推理,计算总体分类准确率并生成混淆矩阵。评估指标扩展至类别级的精确度、召回率、F1分数及特异性,通过结构化报表展示各类别性能差异。最终模型以.mat文件格式保存,包含完整网络结构和训练元数据。 训练结果 本代码在训练的过程中输出了训练的效果: 轮迭代经过的时间 (hh:mm:ss)小批量准确度验证准确度小批量损失验证损失基础学习率1100:00:110.00%14.25%4.20927.68760.001013000:01:1385.94%74.69%0.74491.16080.001015000:01:5284.38% 0.7351 0.001016000:02:1887.50%87.85%0.45180.47320.001029000:03:1892.19%93.13%0.25470.23280.0010210000:03:3796.88% 0.1316 0.0010212000:04:1798.44%94.64%0.09220.18600.0010315000:05:1698.44%95.81%0.05470.14250.0010318000:06:1495.31%95.14%0.15650.16840.0010320000:06:5296.88% 0.1119 0.0010321000:07:1598.44%96.81%0.05270.11680.0010424000:08:1598.44%96.65%0.04430.13630.0010425000:08:3396.88% 0.0663 0.0010427000:09:1398.44%96.31%0.10220.16350.0010530000:10:13100.00%97.40%0.02430.11470.0010533000:11:1196.88%95.64%0.08880.19350.0010535000:11:47100.00% 0.0246 0.0010536000:12:1092.19%95.31%0.16060.18220.0010639000:13:0895.31%97.23%0.14050.15750.0010640000:13:2698.44% 0.0218 0.0010642000:14:0796.88%97.15%0.07800.10280.0010745000:15:07100.00%97.99%0.00310.09660.0010748000:16:0893.75%97.90%0.17250.10110.0010750000:16:43100.00% 0.0019 0.0010751000:17:0698.44%98.41%0.03910.08830.0010854000:18:04100.00%97.40%0.00090.09740.0010855000:18:22100.00% 0.0006 0.0010857000:19:0098.44%97.82%0.05370.08090.0010960000:19:5998.44%97.82%0.31310.12600.0010963000:20:57100.00%94.22%0.00190.19950.0010965000:21:33100.00% 0.0283 0.0010966000:21:5895.31%96.23%0.13730.17650.00101069000:22:56100.00%96.06%0.00040.16650.00101070000:23:1498.44% 0.0493 0.00101072000:23:5598.44%96.73%0.04940.13380.00101175000:24:5698.44%97.49%0.03780.14180.00101178000:25:5496.88%96.98%0.13190.10400.00101180000:26:29100.00% 0.0011 0.00101181000:26:5198.44%96.98%0.05850.21320.00101284000:27:4996.88%98.24%0.04860.07660.00101285000:28:0796.88% 0.1766 0.00101287000:28:4696.88%97.49%0.09580.09320.00101390000:29:4395.31%96.14%0.09570.17840.00101393000:30:51100.00%98.49%0.00030.05000.00101395000:31:2798.44% 0.1496 0.00101396000:31:50100.00%98.58%0.00650.06150.00101499000:32:48100.00%98.83%0.01100.05890.001014100000:33:06100.00% 0.0024 0.001014102000:33:46100.00%98.58%0.00390.06520.001015105000:34:46100.00%98.16%0.01130.06270.001015108000:35:48100.00%99.08%0.00050.04320.001015110000:36:25100.00% 0.0034 0.001015111000:36:48100.00%99.16%0.00750.04090.0010训练结束: 已完成最大轮数。 模型保存完成 评估模型性能... 测试集准确率: 99.08% 准确率: 准确率曲线图片 Loss值: Loss值图片 完整训练进度结果: 训练进度结果图片 Matlab App Designer使用 启动软件之后的界面是这个样子: 软件界面图片 完成识别后的界面: 完成识别后的界面图片 识别结果及日志记录: 识别结果及日志记录图片 下载地址: 包含的内容: 包含的内容图片 购买地址:【Matlab App Designer】基于Matlab卷积深度学习的交通标志识别|数据清洗+模型优化,准确率99%
-
【中国交通标志数据集TSRD下载】上海交大网盘高速下载+58类6164张标注图像 本文详细解析中国交通标志识别基准数据集TSRD,提供官方下载与上海交通大学网盘高速下载双通道。该数据集包含58类共6164张高质量标注图像(4170训练集+1994测试集),每张图片均提供精准坐标标注文件,特别适合交通标志识别算法开发、自动驾驶模型训练及计算机视觉研究。内含数据目录结构解析、标注文件格式说明,助您快速开展深度学习实战。 数据集说明 TSRD包括6164幅交通标志图像,包含58个标志类别。图像分为训练数据库和测试数据库两个数据库分库。训练数据库包括4170幅图像,测试数据库包含1994幅图像。所有图像都标注了标志和类别的四个坐标。 数据集下载 (1)官网下载地址: TSRD-Train TSRD-Test TSRD-Train Annotation TSRD-Test Annotation (2)上海交通大学网盘地址: Chinese Traffic Sign Database - 上交网盘版 包含的内容图片 数据说明 我看了看下载的数据集,分类使用前面的000、001这样进行区分的,一共是58个标志类别,因此是000~057,一共58个。 数据集里的图片 关于标注文件(TSRD-Test Annotation.zip和TSRD-Train Annotation.zip)中内容的解释: 当前格式应为: 文件名; 图像宽度; 图像高度; 左上角x; 左上角y; 右下角x; 右下角x; 类别 标注的数据集图片